신경망 학습
입력노드에서 뉴런 모델들 카운트 후에 오른쪽에서 왼쪽으로
입력은 뉴런이 없기에 층수에서 제외
개, 고양이 판단하게 두고 입력데이터와 정답을 알려주고 가중치의 값이 최적값을 위해 반복 학습해라고 하면 역전파 알고리즘으로 텐서플로우가 자동으로 미분해주고 구함 입력층과 중간층 사이에 w값을 랜덤으로 뿌림 그리고 값이 개가 나올수도 아닐수도 -> 오차를 구하고 1과 0 으로 나옴 확률으로 나옴으로 오차를 구한다 모든 데이터의 오차를 구하고 오차 신호를 역전파 알고리즘에 보내주고 한 번 학습 보통 콜백 함수 써서 오차가 줄지 않을 때까지
신경망 학습
- 학습이 잘 된다는 의미는 좋은 가중치 값을 구하여 신경망의 출력층 이 원하는 목표치와 점점 가까운 최적의 값을 출력하는 것
- 처음에는 가중치에 임의의 랜덤(random)한 값들을 설정하였으나, 학 습과정을 통해 점차 일정한 값으로 수렴하여 최적의 가중치 값을 찾아감

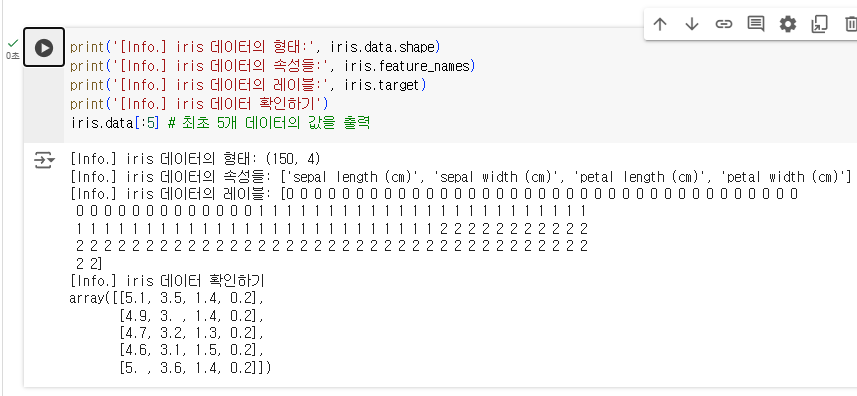
심층 신경망(deep neural network)은 뉴런 모델들로 이루 어진 층 수가 최소 3 개 이상으로, 다수의 은닉층들을 포함 하는 깊은 계층으로 구성된 신경망의 총칭을 의미

이러한 심층 신경망을 사용한 머신러닝 알고리즘을 딥러닝이라고 부름
신경망을 깊게(deep) 쌓았다고 해서 딥러닝이라고 부름
딥러닝은 최근의 GPU 와 같은 컴퓨터 하드웨어 기술과 향상과 빅데이터 생태계의 활성화로 현재까지 발전되고 있음
인공신경망 모델 실습
- 텐서플로우 (Tensorflow)
신경망 모델을 구현하고 학습하기 위한 파이썬 기반의 오픈소스 머신러닝 라이브러리로 텐서플로우(Tensorflow)가 유명함
텐서플로/ 케라스 핵심 함수 이해
- 케라스에서 레이어(layer)를 구성하는 방법으로 사용되는 핵심적인 자료 구조형 은 모델(model)
- Sequential 모델은 레이어를 선형으로 연결하여 구성(가장 간단한 방법)
0) Sequential 모델
1) Dense 신경층 구성 함수
2) 학습 알고리즘 함수 : compile ,optimizer ,sgd 방법
3) 자동으로 학습하는 함수 : fit()
4) 모델 성능 평가 함수 (모델이 잘 맞추는지) : evaluate
5) 서비스 실행 및 예측 : predic()
붓꽃 분류기 구현
- 세 붓꽃 종의 이름은 Versicolor, Setosa, Virginica
- 각 종에 따라 꽃받침의 길이와 너비, 꽃잎의 길이와 너비가 약간씩 차이
- 꽃받침과 꽃잎의 크기를 측정한 데이터를 기반으로 새로운 종을 분류하는 신경망 모델을 구축
- 각각의 속성은 꽃받침 길이sepal length와 너비sepal width및 꽃잎 길이petal length와 너비petal width를 cm 단위로 측정한 값
데이터를 여러 개 학습 (한 개씩 하지 않음)
또 데이터 입력 출력은 가로로 넣고 나옴
데이터가 기본 데이터는 128개 묶어준다 (10개씩이든,20개씩이든,,)
예를 들어) 데이터 행렬 입력 5x4 는 출력 5x3 나온다 (행이 증가하는 방향으로 행이 넣어준 만큼 10행 -> 출력도 10행
실습

후 드라이브 연결
13기가
layer 는 층 만듬
객체 - 객체란 안에 다양하게 들어간다.
설명
shape 로 행렬의 크기
데이터 실행 데이터,시험데이터는 시험할 때 쓴다.
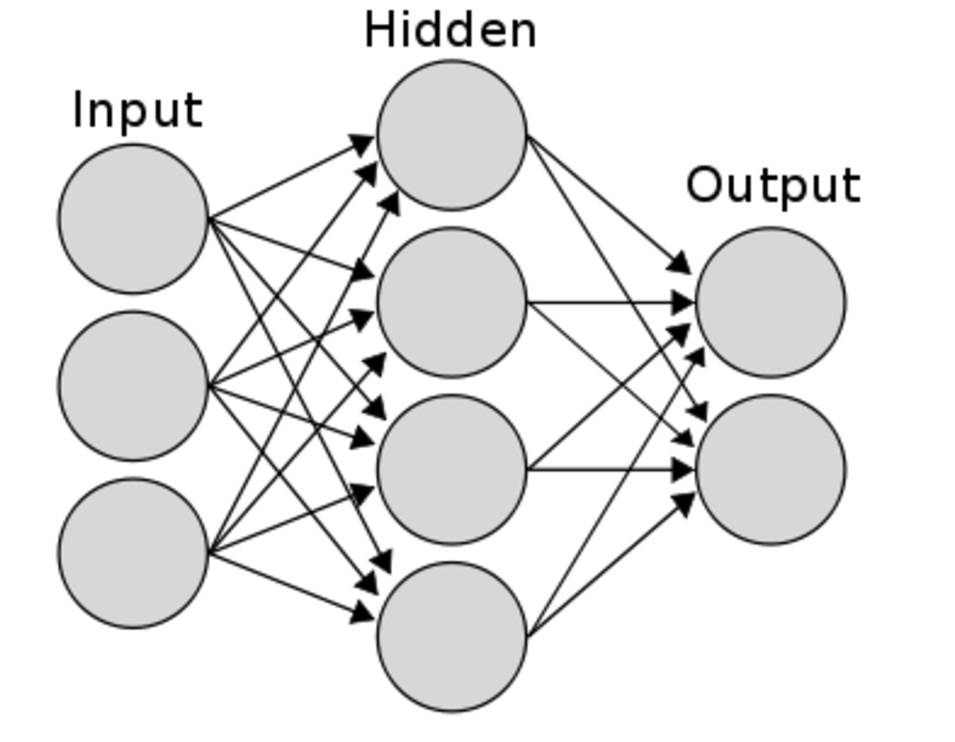
target은 변수 , 0은 viginica, 1은 세토사 , 2는 버시컬러 이런식으로
150 x 4 행렬 에서 iris.data [:5] 의 의미는 한 줄부터 4줄까지 뽑아라

train_test,x에 수집한 데이터 넣고 y에 답 넣고 test_size = 0.2 (20프로만 즉 120개 시험데이터 나머지만 학습에 쓰겠다)
random_state=1 은 랜덤으로 섞기
X_train (1x120) y_train 일대일 대응X_test (30 x3 행렬)
y_test ------평가
데이터 정규화 해주어야함평균0이고표준편차1


X_train -= mean X_test -= mean 평균값 0으로 만들고
X_train /= std 표준편차 1로 만들어 준다
열에 대한 평균값(axis = 0)
X_train -= mean 은 X_train은 각 칼럼(X_train)별의 평균값을 뺀값이다.
두번째 열은 각 열마다 3.019,, 빼줌
첫번째 열은 각 열마다 5.8383,,, 빼줌
시험 데이터는 미래 데이터 및 학습하지 않은 데이터이기에
학습데이터의 평균값과 표준편차를 이용
붓꽃 분류를 위한 인공신경망 모델 구현 및 실습
- 신경망 모델 설계하기
- 신경망 모델 컴파일 하기
- 신경망 모델 학습하기
- 학습한 신경망 모델 성능 평가하기
- 학습한 모델 저장하기

param 가중치
(none, 1000) 행으로 몇개 넣을지 모르기 때문에 각 층을 통과할 때마다 갯수 넘어감
-손실함수 설정
- 옵티마이저 (optimizer) - adam 함수 불러서

함수들
수학적으로 는 RMSprops가 좋다 하지만 ADAM으로 많이 함
3개 정도
RMS 단점 관성이 없다
ADAM 은 적응성과 관성도 가지고 있다
SGD 관성이 있다
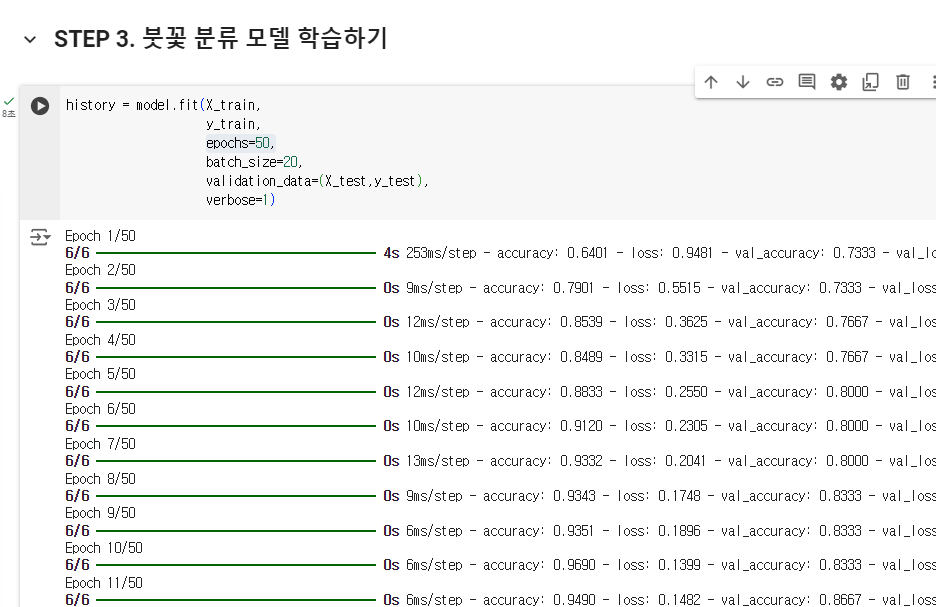
50번 반복
행 20개씩 하겠다
매 에모크 마다 validation _data - 시험데이터에 대한
verbose =1 은 줄 하나
'딥러닝실무응용 > 딥러닝' 카테고리의 다른 글
| [딥러닝] 실습(3) (0) | 2024.08.21 |
|---|---|
| [딥러닝] 실습(2) (0) | 2024.08.21 |
| [딥러닝] 인공신경망 기초 (0) | 2024.08.16 |
| [딥러닝] 넘파이(Numpy) 배열 실습 (0) | 2024.08.16 |
| [딥러닝] #02 넘파이(Numpy) 배열 기초 (0) | 2024.08.14 |



